
파이썬을 통한 pdf 파일 합치는 방법
왜 Pypdf인가?
제가 일을 할 때 가끔씩 pdf 파일을 병합하거나 혹은 페이지별로 분할하거나 텍스트를 인식해서 검색해야하는 경우가 있었어요.
이럴 때 보통 인터넷에서 pdf파일 병합을 검색하면 어도비가 나오거나, small pdf, 웹으로 병합해주는 사이트 등이 있는데 각기 다른 문제점이 있었어요
어도비를 통해서 pdf파일을 병합, 분리하게 된다면 일정 기간동안 락이 걸려서 결제를 하게 유도해요
그리고 락이 걸리는 기준은 ip주소인지 캐시 기록인지 어떤 기록인지 모르겠지만 거의 1주일 넘게 락이 걸려요
스몰피디에프라는 사이트도 어도비랑 마찬가지인데 몇 회 이상 하고나면 일정기간 쓰지 못하게 락이 걸리며 결제를 유도해요
그러면 남은건 pdf파일합치기라고 검색해서 나오는 웹사이트에 pdf파일을 그래그앤드롭 한다음에 병합하는건데
횟수는 제한이 없는대신, 조금 찝찝함이 있잖아요?
예를 들자면 개인정보나 민감정보가 있는 PDF파일을 업로드하면 해당 서버에 저장이 되지않는지, 유출이 되지 않을지
그래서 저는 pypdf를 써요
pdf 병합 - Colab에서(노가다 코드)
from PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMerger
merger =PdfFileMerger()
merger.append(PdfFileReader(open("분할한1 PDF 파일556.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일557.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일558.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일559.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일560.pdf", 'rb')))
merger.write("output01.pdf")
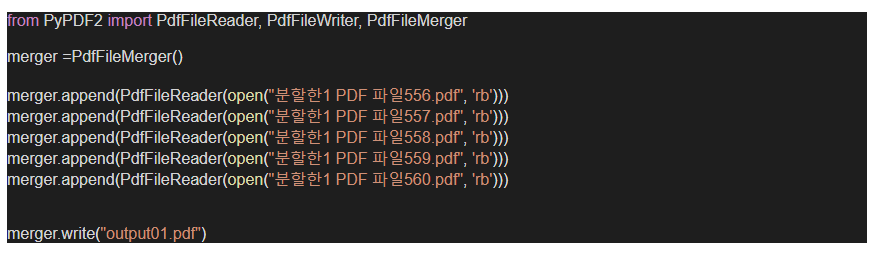
위 첫번째 사진은 코드는 코랩을 통한 pdf병합 방법이며 노가다 코드입니다.
복붙을 위한 코드는 2번째 박스를 드래그 하시면 돼요
상세 설명이나 순서는 밑에서 지속적으로 설명할게요

먼저, 코랩을 실행 시킨 뒤 파일 모양의 버튼을 눌러주시고 화살표가 있는 곳에 드래그 앤 드랍을 해줘요
from PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMerger
merger =PdfFileMerger()
merger.append(PdfFileReader(open("분할한1 PDF 파일556.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일557.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일558.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일559.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일560.pdf", 'rb')))
그리고 코드를 입력해줘요
해석하면 pdfFileReader, pdfFilewriter, pdfFilemerger를 불러오겠다. 라는 느낌입니다.
merger.append(PdfFileReader(open("분할한1 PDF 파일556.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일557.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일558.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일559.pdf", 'rb')))
merger.append(PdfFileReader(open("분할한1 PDF 파일560.pdf", 'rb')))
그리고 코랩에 업로드한 파일을 입력해줘야해요
저는 pdf파일명이 분할한1 PDF 파일559.pdf 라서 저렇게 적었어요
예를들면 합치고자하는 pdf 파일 이름들이 등본.pdf , 가족관계증명서.pdf면
merger.append(PdfFileReader(open("등본", 'rb')))
merger.append(PdfFileReader(open("가족관계증명서", 'rb')))
이렇게 입력하면 되겠죠?
merger.write("output01.pdf")
그리고 마지막 코드입니다.
해석하면 합친 pdf 파일을 이름을 정하는거에요
즉 분할한1 PDF 파일 556~560.pdf를 합쳤을 때 파일 이름을 output01.pdf로 하고싶다 라는말이에요
자 그러면 바로 위의 등본, 가족관계증명서를 합치고 그 파일 이름을 제출서류.pdf라고 하고싶으면
merger.write("제출서류.pdf")라고 적어주면 돼요
그런데 여기서 문제가 하나 발견되는데요

저렇게 파일 이름을 하나하나 노가다로 쳐야하는데 노가다 하기가 힘들겠죠? 그래서 코드를 개선했어요
pdf 병합 - Colab에서(노가다 코드 개선)
from PyPDF2 import PdfFileReader, PdfFileMerger
merger = PdfFileMerger()
for i in range(556, 560):
filename = f"분할한1 PDF 파일{i}.pdf"
merger.append(PdfFileReader(open(filename, 'rb')))
merger.write("output.pdf")
위와 같은 코드로 입력하면 돼요 조금만 설명하자면
for i in range(556, 560):
분할한1 PDF 파일 556.pdf ~ 분할한1 PDF 파일 560.pdf 을 하나하나 치기 오래걸리고 이게 1000장이 넘으면 그냥 노가다니까 저렇게 반복문을 활용해서 숫자 범위만 지정해주면 한번에 하겠다. 라는 말이에요
그러면 여기서 또 문제, 내 폴더에는 저렇게 파일들의 이름이 깔끔하게 정리되어 있지도 않고, 중구난방이다 어떻게 불러워와야할까?
from google.colab import files
import os
from PyPDF2 import PdfFileReader, PdfFileMerger
# "증명서" 폴더 내의 모든 PDF 파일을 콜랩에 업로드합니다.
uploaded = {}
for filename in os.listdir("증명서"):
if filename.endswith(".pdf"):
with open(os.path.join("증명서", filename), "rb") as f:
uploaded[filename] = f.read()
# 새로운 PdfFileMerger 객체를 만듭니다.
merger = PdfFileMerger()
# 업로드된 각 PDF 파일을 반복하며 병합 개체에 추가합니다.
for filename, contents in uploaded.items():
# 읽기 모드로 PDF 파일 내용을 엽니다.
pdf_file = PdfFileReader(contents)
# PDF 파일을 병합 개체에 추가합니다.
merger.append(pdf_file)
# 병합된 PDF 파일을 디스크에 저장합니다.
output_file = "merged_output.pdf"
with open(output_file, 'wb') as f:
merger.write(f)
print(f"'증명서' 폴더 내의 모든 {len(uploaded)}개 PDF 파일이 {output_file}로 병합되었습니다.")
이 코드는 os.listdir() 및 endswith() 메서드를 사용하여 "증명서" 폴더 내의 모든 PDF 파일을 반복문으로 가지고 올 수 있어요
각 PDF 파일에 대해 with open() 문을 사용하여 파일 내용을 읽고, 파일 이름을 키로 사용하여 uploaded해서 추가 해요
그런 다음 새 PdfFileMerger 개체를 만들고
for문을 사용하여 각 업로드 된 PDF 파일을 루프해서 가지고 올 수 있어요
반복문(루프) 내부에서는 PdfFileReader()를 사용해서 읽기 모드로 PDF 파일 내용을 열 어요
그리고, 위에 코드와 똑같이 append() 메서드를 사용하여 merger 개체에 pdf 파일을 추가했어요
마지막으로 병합 된 pdf 파일을 작업 디렉토리에 "merged_output.pdf"라는 이름으로 저장하고, 몇 개의 pdf파일이 병합됐는지, 출력 된 파일의 저장위치를 나타나는 메세지를 출력(인쇄)했어요
긴 글 읽어주셔서 감사합니다.
그리고 pdf분할 방법은 아래 url을 클릭해주세요
추가코드
from PyPDF2 import PdfMerger
pdfs = ['file1.pdf', 'file2.pdf', 'file3.pdf', 'file4.pdf']
merger = PdfMerger()
for pdf in pdfs:
merger.append(pdf)
merger.write("result.pdf")
merger.close()
보다 직관적으로 볼 수 있는 코드 수정하였습니다 (23.06.02)
Python을 활용한 PDF 합치기
파이썬을 통한 pdf 파일 합치는 방법 글의 순서 1. 왜 PyPDF인가 2. pdf 병합 - Colab에서(노가다 코드) 3. pdf 병합 - Colab에서(노가다 코드 개선) 4. 병합시 문제점 보완 1. 왜 Pypdf인가? 제가 일을 할 때 가
madanhambo.tistory.com
PDF 분리 방법 | pdf 페이지 나누는 방법
파이썬으로 pdf파일 분리하는 방법 이전에 pdf파일 병합 코드를 작성한적이 있고, 그 글의 연장선인 pdf파일 분리코드를 적어보고자 해요 이전 글은 아래 URL을 참조해주세요 https://madanhambo.tistory.co
madanhambo.tistory.com
'IT > Python' 카테고리의 다른 글
| 파이썬으로 Pdf 텍스트 추출 법 (0) | 2023.05.21 |
|---|---|
| Python을 활용한 PDF 분리하기 (Pdf나누기) (0) | 2023.04.27 |


댓글